

Making Machine Learning Concepts Accessible
Cutting-edge advertising technology is often marketed as "powered by Artificial Intelligence." Some marketers get scared away, believing that they aren't prepared or educated enough to leverage the latest tech. However, many marketing and advertising applications of Artificial Intelligence (AI) lean heavily on a subset of AI called Machine Learning. Essentially, Machine Learning (ML) is about improving predictions from the data you already own. As a decision maker within your organization, you should understand what basic ML applications entail and how they can be properly employed.
This blog post will cover three basic ML applications:
- Regression
- Classification
- Clustering
We'll explore some use cases and avoid grandiose concepts that are too complicated to execute when getting started. I believe that beginning any Machine Learning endeavor requires baby steps. Like all technology development, it's an iterative process that requires due diligence, realistic expectations, and never-ending trips back to the drawing board. Most importantly, this information should provide marketers with a reasonable understanding of ML concepts so that you feel empowered to make educated decisions when investing in projects.
Making Predictions with Regression
Regression is the process of estimating the relationship between variables. For example, a basic Return on Ad Spend (ROAS) model: given $100 of ad spend (X), how much revenue can I expect to generate (Y)?
Another useful example is predicting morning traffic. How much does the length of my commute increase for every inch of rain, day of the week, or time of departure? Traffic and ROAS predictions for that matter depend on more than just one single input variable. These models can combine tens and possibly hundreds of variables. Predicting ROAS could be a function of budget, time of day, average frequency caps per user, site content ratings, ad visibility, ad size, button color, ad copy, etc. This is known as MULTIPLE REGRESSION.

or time of departure affect commute time. (Photo credit: Wikipedia)
The beauty of multiple regression is that the model dictates the relative importance of each input in determining the output variable or prediction variable (e.g., ROAS or commute time). Simply stated, regression is best used when attempting to forecast a result.
You might hear analysts or data scientists talk about regression analysis to predict future performance. Regression uses historical data points to create a model that allows a program to plug values into the weighted equation and get back a predicted result.
Using the example above, let's say we’ve determined that our ROAS metric is on-site revenue ($OSR). We've trained our regression model with some of the possible variables considered above. Let’s assume our model is:
$OSR = (1.03 * budget) - (0.05 * time of day) + (0.63 * avg. frequency caps per user) + (0.005 * site content rating)
In making a prediction for on-site revenue generated, you could plug any combination of values into this equation and get a predicted amount of on-site revenue ($OSR).
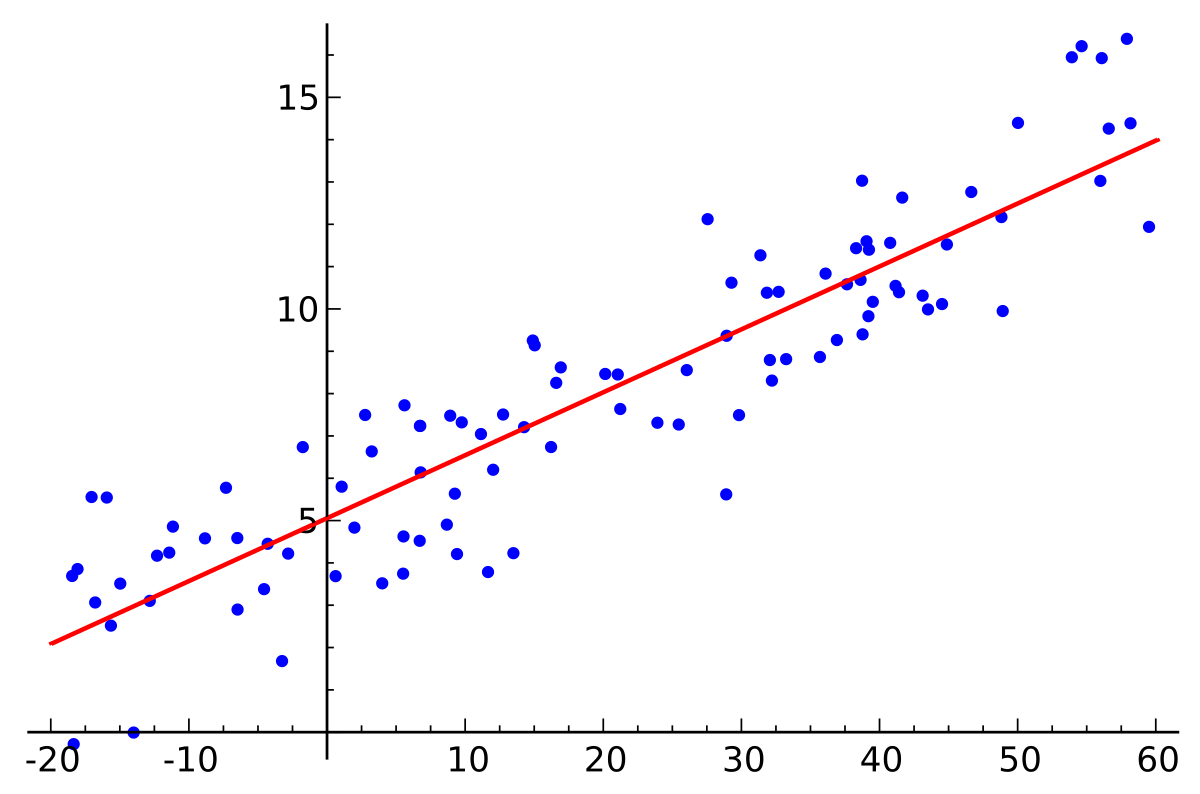
Any machine learning system should constantly re-train on new data, as results are always changing and the relative importance of each input variable can change significantly based on actual results. The model should adapt as your data changes. Your predictions are only as good as the data you feed the system.
Classification
Classification is a form of categorization via pattern recognition. At its simplest form, logistic regression is the model of choice for determining the likelihood that something is either Category A or Category B.
A common example might be an email spam classifier. A more relevant example for advertising would be a classifier that determines the probability of a user converting after seeing an ad. This type of classifier powers the automated bid optimizers found in many DSPs. In theory, such a classifier would take an array of inputs related to a user —often gleaned from detailed cookie data— and provide a probability or likelihood of conversion. The higher the likelihood of conversion, the more your DSP is willing to pay for the impression and thus a higher bid. However, not all classification has to happen within an auction.
If you're curious to get a deeper dive into how supervised classification algorithms work, this video from Wolfram walks through several examples:
On-site experiences can be significantly improved by employing classification. Understanding who is visiting your site by age, gender, location, estimated income level, interests, and so forth can help you tailor on-site content such as text, images, calls to action, recommended products, and much more. No classification system is going to be 100% accurate, but even a slight improvement in UX that can be driven by a classification system can move the needle in terms of revenue.
Enterprise analytics platforms (such as Google Analytics 360 or Adobe Analytics) often offer demographic reporting that marketers find useful. These reports are often driven by a combination of classification and clustering algorithms employed together.
What's the Difference Between "Supervised" and "Unsupervised" Machine Learning?
In the case of classification, "supervised" ML means that the algorithm is provided with preset classification labels or categories. The classification algorithm can then work through a data set and classify items according to the available labels and categories.
On the other hand, "unsupervised" ML is required when there is a data set, but the categories, patterns, or meaningful relationships that might exist in that data set are unknown before the algorithm (e.g., clustering algorithm) has run.
Clustering
Classification and regression are typically SUPERVISED learning models, meaning the input data is labeled for a particular set of outputs. Clustering algorithms are UNSUPERVISED—the process of finding patterns and hidden structure within unlabeled data. Think of unsupervised models this way: "What patterns can I find in a set of data that I don’t already know much about?"
Audience or customer segmentation are prime examples of applied clustering. Your Customer Relationship Management (CRM) system is filled with a breadth of customer-related information. Wouldn't it be valuable to figure out who you should reach out to for a customer loyalty promotion? Or, what kind of client is likely to churn and what can you do to retain their business?
Clustering algorithms can identify the similarities between your users/customers and group them accordingly. K-means clustering is a simple but powerful algorithm that can be implemented with minimal inertia. While k-means clustering is often a stepping stone to more sophisticated clustering algorithms, it can whet the appetite for what can be further uncovered.
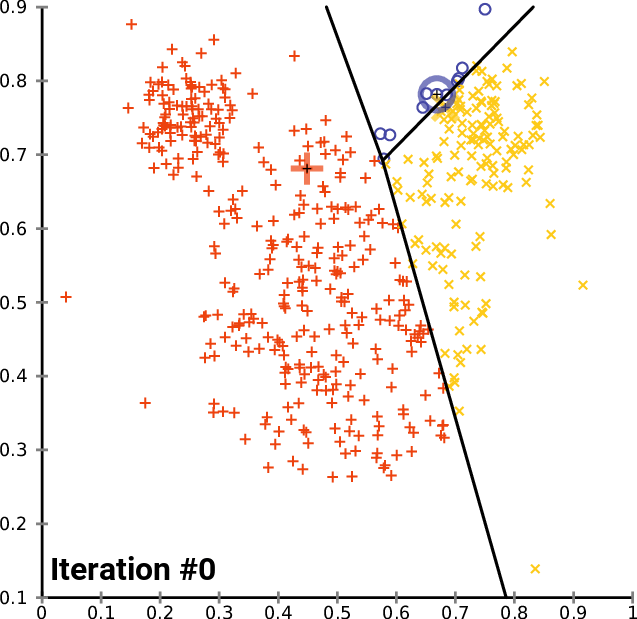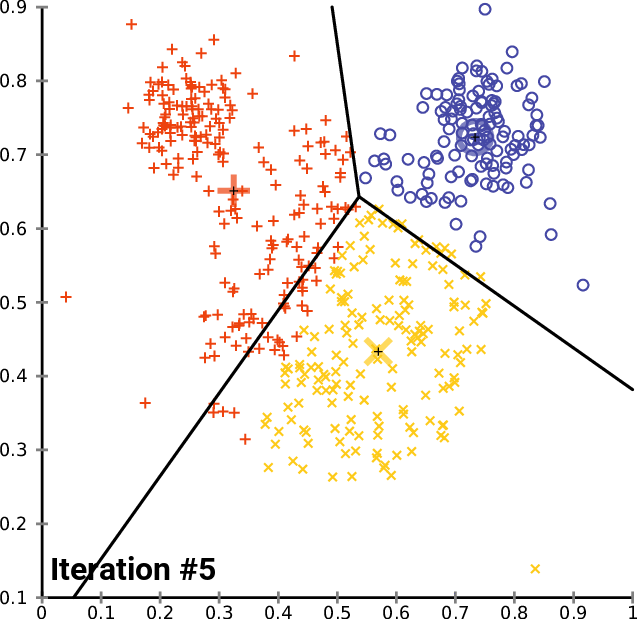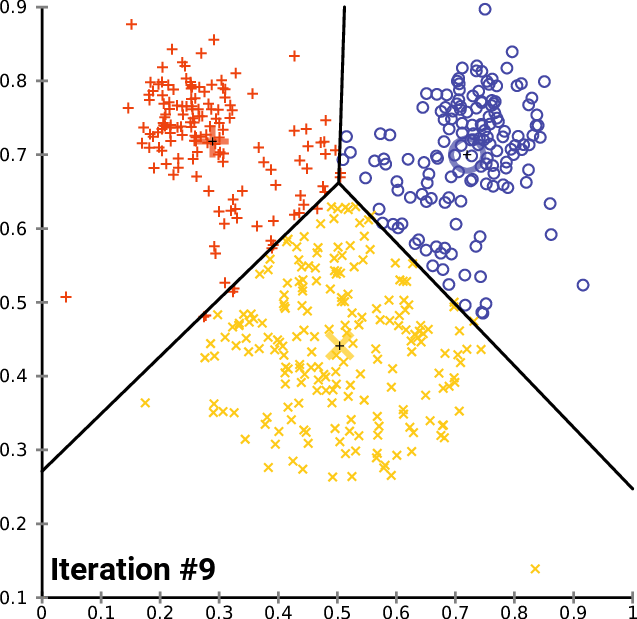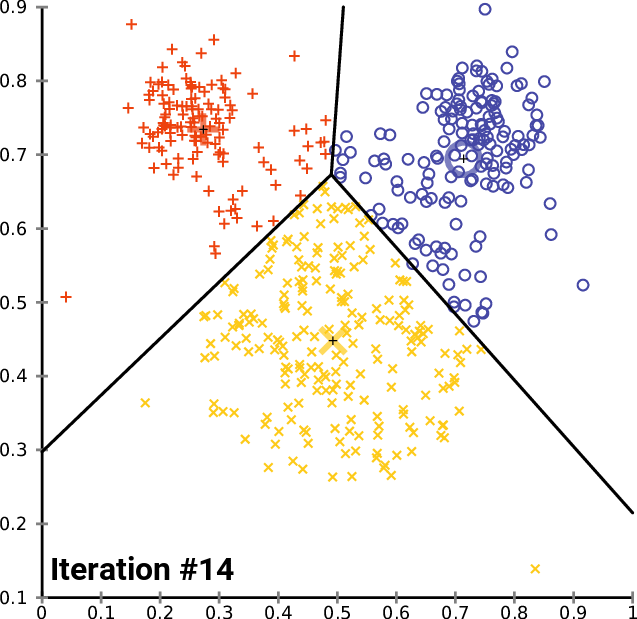
Distribution models employ a more statistical approach to clustering, where membership is probabilistic and members can belong to more than one cluster. Distributive clustering is actually quite useful in audience segmentation. Your users may exhibit behavior that is commonly found in high-revenue customers but may also exhibit behavior in customers that are likely to leave for a competitor.
Machine Learning Doesn't Just Work Right Out of the Box
No machine learning system is complete without cross-validation, feature reduction (removing variables that don't impact the model), and other techniques that improve the accuracy of predictions. Ensemble machine learning systems (that blend multiple ML approaches) are increasingly more complex and sophisticated and often require the help of experts to develop and maintain. It’s important to understand and start with the basics and decide if machine learning is worth the investment for your organization.
Taking the Next Step with Machine Learning
You should now have a better grasp of common Machine Learning algorithms and their everyday applications in marketing and advertising. Getting started may seem daunting, and with the volume and depth of data at your disposal, hiring an expert to get you off the ground can pay major dividends to your business now and in the future. Exciting breakthroughs by ML practitioners and the availability of open sourced, enterprise-quality SDKs (such as and StatsModels and scikit-learn), along with scalable cloud infrastructure at your disposal, has made it easier than ever to discover what insights your data may hold.