

Some years ago, as digital storage grew more affordable, the attitude towards data by many companies was to “store everything.” Every. Single. Data. Point.
Next came “big data” and cloud computing, which brought even more data, more computing power, and ostensibly more opportunity and insights. As a result, data consumption skyrocketed, driven by the Internet, social networks, and digital services.
To paraphrase my guru Avinash Kaushik, we now have more data than God ever intended anyone to have.
The instinct to store everything is understandable. Why throw away data? But there have been a few unforeseen effects:
- It increases the workload associated with data quality assurance
- It increases data processing times
- It makes data sets more complex and more difficult to work with
- Most of the data is irrelevant to business analysis
The decision to keep all the data was an easy one. Discerning which data points should be considered is difficult. This consideration phase will be implemented either as companies are specifying a data project (BEFORE), or as they introduce a new release of their digital assets (AFTER).
For mature audiences only
Imagine you’re building the specification for your project and figuring out how to measure project success. You will most likely consider the following KPIs:
- Key feature usage rate (conversion rate)
- Marketing effectiveness (budget, cost per acquisition)
- Vanity metrics (volume, users)
Sounds too basic? Fair enough. And yet that’s a great base to work from!
Important Tip: Your project must be in sync with your organization’s maturity level.
First, you need to make sure the basic data you intend to collect from your site or app resonates with your product managers, your marketing team, or your analysts. They need to understand how these basic numbers can help shape your product or marketing strategies.
Then, a specification document must be established. A Data Collection Bible of sorts. Call it a tagging plan, a data collection blueprint, a solution design document… get creative! That document will not be set in stone. It will evolve with your company as you enrich your data set to meet your measurement requirements. Make sure to include significant stakeholders in that process, or else...
Only after you’ve gone through a thorough data specification phase can you consider enriching your data during subsequent development cycles. Data enrichment will either be:
- Vertical: more metrics to measure specific user events
- Horizontal: more dimensions/attributes to give metrics more context
Keep enriching your data to assess the KPIs that support the measurement of your business objectives. Give them as much context as you can so the analysis is as relevant and actionable as possible.
Does your data spark joy?
All this talk about enriching your data sounds great, but you may be at a stage where you’ve collected way too much data already. Arguably, getting a ton of data means getting the fuel to power machine learning, artificial intelligence, or any reasonably advanced data processing.
Having said that, too much unidentified/non-cataloged data will ultimately yield confusion and storage/processing costs. For instance, if you have a contract with a digital analytics vendor (say Adobe or Google), it is very likely you’re paying a monthly/yearly subscription fee based on the number of hits your system collects and processes into reports, cubes, and miscellaneous datasets. Additionally, digital marketing teams are not known for questioning the status quo when it comes to data and tracking, in particular.
If you combine both facets of data cleanup, we’re looking at an optimization campaign that turns into a cost-saving effort. This is where you as a company should start asking yourself: “do I really need that data? Can my team function without measuring metric X and attribute Y?”
To borrow from Marie Kondo’s konmari method, you should keep only data points that speak to the heart. Identify metrics/attributes that no longer “spark joy," thank them for their service before brutally disposing of them with a firm and satisfying press of the DELETE button.
How can you tell whether you should discard a specific data point?
This requires a bit of investigation that can be done in your data repository by looking at your data structure (column names and values for instance). If you cannot make up your mind, ask yourself whether one particular data point really “sparks joy,” or in our case, drives analysis and can be used as a factor in machine learning. In fact, this is a great occasion to actually use machine learning to find out!
Feed your data set into R/Python (insert your favorite machine learning package here) and look at the results:
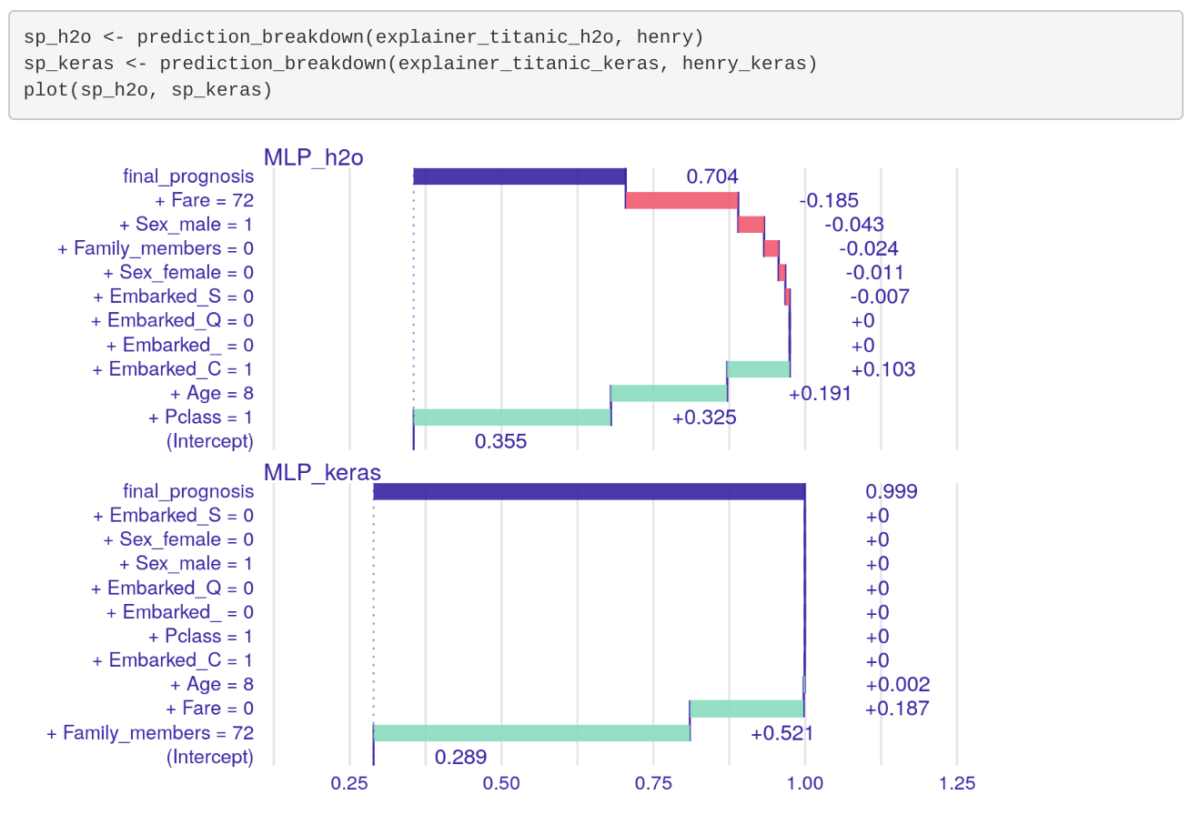
You could also look at factor analysis another way and see where a specific factor really contributes to performance, metric by metric:
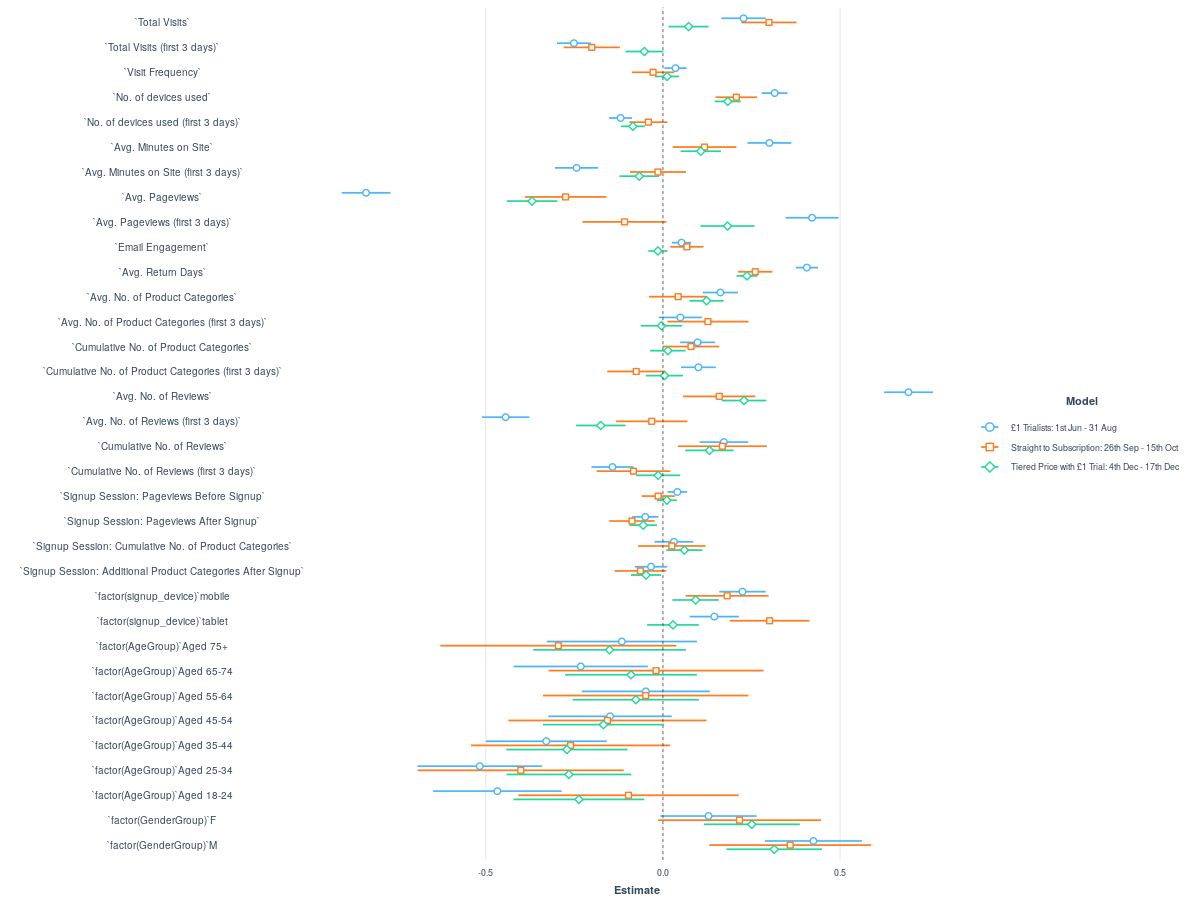
Once you’re done analyzing which data points still belong in your data architecture, it’s time for pruning. If you have made the decision to delete existing data, this can be as simple as deleting a column or a set of entries in a database, data lake, or data repository. But that’s only for data you already collected. What about data collection moving forward?
If you want to change the way data is collected, you need to go konmari on your digital assets: web site tracking, mobile SDKs, OTT devices. Using a tag management system (TMS), you can start by deactivating/pausing tags you no longer need before safely deleting them from future versions:
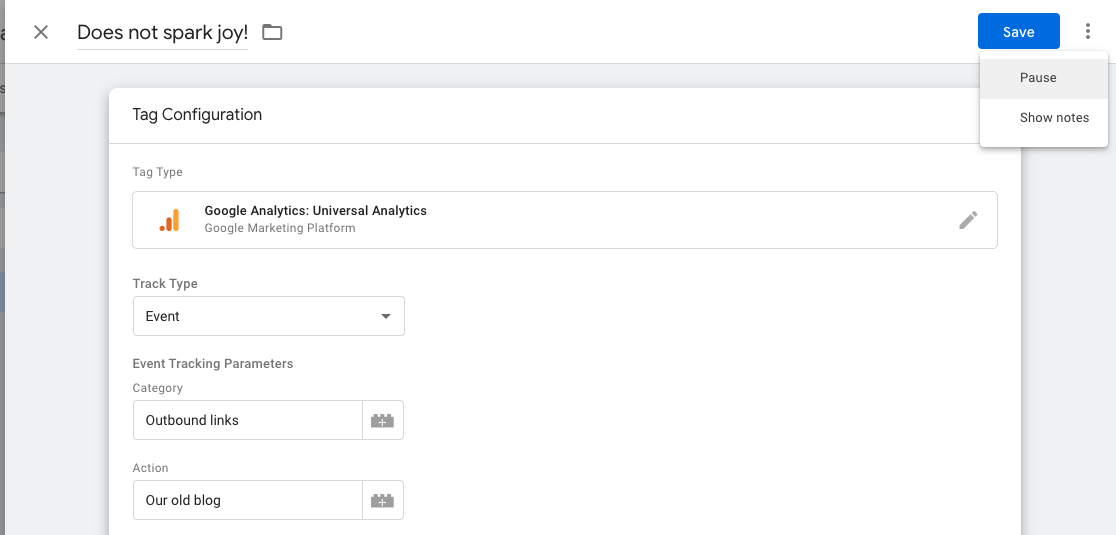
From a management perspective, stakeholders need to make themselves known and express clear data requirements that can easily be retrieved. That way, when you prune/retire data that is deemed to no longer spark joy, you’re not inadvertently sabotaging your colleagues’ reports.
And this is why you needed that Data Collection Bible in the first place!
Which data stage are you at? Before or after? Basic or complex? Don’t hesitate to contact MightyHive for a data maturity audit or a digital analytics health check!